Enum vs Stream
The Enum and Stream modules have some of the same functions like each/2, map/2, filter/2 and more. What’s the difference? To help see the difference, let’s look at a simple example. First we’ll look at how Enum works and then compare it to Stream.
Contents
Enum and piping a list
When we pipe a list using the Enum.map/2 function, we can peek into the process by using IO.inspect/2 to see the order of execution and what each step returns.
This example uses IO.inspect/2 inside the functions being executed and between each step. With this we can better visualize what is happening.
defmodule Playing do
def peeking_into_enum() do
[1, 2, 3, 4, 5]
|> IO.inspect(label: "ORIGINAL DATA")
|> Enum.map(fn(num) -> IO.inspect(num + 10) end)
|> IO.inspect(label: "STEP 1 RESULT")
|> Enum.map(fn(num) -> IO.inspect(num * 2) end)
|> IO.inspect(label: "STEP 2 RESULT")
|> Enum.map(fn(num) -> IO.inspect(to_string(num)) end)
|> IO.inspect(label: "STEP 3 RESULT")
end
end
Playing.peeking_into_enum
#=> ORIGINAL DATA: [1, 2, 3, 4, 5]
#=> 11
#=> 12
#=> 13
#=> 14
#=> 15
#=> STEP 1 RESULT: [11, 12, 13, 14, 15]
#=> 22
#=> 24
#=> 26
#=> 28
#=> 30
#=> STEP 2 RESULT: [22, 24, 26, 28, 30]
#=> "22"
#=> "24"
#=> "26"
#=> "28"
#=> "30"
#=> STEP 3 RESULT: ["22", "24", "26", "28", "30"]This makes it clear that it works probably exactly like you expected. It visits each element in the list and runs the function on the value. At the end of each step, we have a new list with the transformation applied.
This is called an eager evaluation.
In eager evaluation, an expression is evaluated as soon as it is bound to a variable.
https://en.wikipedia.org/wiki/Eager_evaluation
This was probably the behavior you expected because it is common in most traditional programming languages.
When is “eager” a problem?
Eager evaluation is the default approach used in Elixir. Why would I want a different strategy? When would “eager” be a problem?
Eager evaluation causes problems when the data is very large, possibly even unbounded. Using Enum for each step that we evaluate makes everything happen in RAM. When working with large data sets this can be a problem.
The Stream module gives us an elegant way to do lazy evaluations.
Lazy evaluation, or call-by-need is an evaluation strategy which delays the evaluation of an expression until its value is needed.
https://en.wikipedia.org/wiki/Lazy_evaluation
Eager evaluation causes problems when the data is very large, possibly even unbounded.
Stream and piping a list
Let’s adapt the Enum code from above to now use Stream and see the difference.
defmodule Playing do
def peeking_into_stream() do
[1, 2, 3, 4, 5]
|> IO.inspect(label: "ORIGINAL DATA")
|> Stream.map(fn(num) -> IO.inspect(num + 10) end)
|> IO.inspect(label: "STEP 1 RESULT")
|> Stream.map(fn(num) -> IO.inspect(num * 2) end)
|> IO.inspect(label: "STEP 2 RESULT")
|> Stream.map(fn(num) -> IO.inspect(to_string(num)) end)
|> IO.inspect(label: "STEP 3 RESULT")
end
end
Playing.peeking_into_stream
#=> ORIGINAL DATA: [1, 2, 3, 4, 5]
#=> STEP 1 RESULT: #Stream<[
#=> enum: [1, 2, 3, 4, 5],
#=> funs: [#Function<48.51129937/1 in Stream.map/2>]
#=> ]>
#=> STEP 2 RESULT: #Stream<[
#=> enum: [1, 2, 3, 4, 5],
#=> funs: [#Function<48.51129937/1 in Stream.map/2>,
#=> #Function<48.51129937/1 in Stream.map/2>]
#=> ]>
#=> STEP 3 RESULT: #Stream<[
#=> enum: [1, 2, 3, 4, 5],
#=> funs: [#Function<48.51129937/1 in Stream.map/2>,
#=> #Function<48.51129937/1 in Stream.map/2>,
#=> #Function<48.51129937/1 in Stream.map/2>]
#=> ]>Wow. That output looks really different! A big thing to note is it hasn’t actually executed any of the functions!
At each step, instead of returning a transformed list where each element had the function applied to it, we get a data structure.
The Stream data structure contains the thing to enumerate as enum and it builds up a list of functions that we want applied in funs. Notice that at each step, the only thing that changes is that another function was added to the list.
How do we make a Stream actually do work?
The Stream data structure also implements the Enumerable protocol. This means we can use the Enum module to use our lazy definition and actually apply some demand to the stream making it evaluate. To do this, we can add one more pipe that pipes our stream into Enum.to_list/1.
defmodule Playing do
def peeking_into_stream() do
[1, 2, 3, 4, 5]
|> IO.inspect(label: "ORIGINAL DATA")
|> Stream.map(fn(num) -> IO.inspect(num + 10) end)
|> IO.inspect(label: "STEP 1 RESULT")
|> Stream.map(fn(num) -> IO.inspect(num * 2) end)
|> IO.inspect(label: "STEP 2 RESULT")
|> Stream.map(fn(num) -> IO.inspect(to_string(num)) end)
|> IO.inspect(label: "STEP 3 RESULT")
|> Enum.to_list()
end
end
Playing.peeking_into_stream
#=> ORIGINAL DATA: [1, 2, 3, 4, 5]
#=> STEP 1 RESULT: #Stream<[
#=> enum: [1, 2, 3, 4, 5],
#=> funs: [#Function<48.51129937/1 in Stream.map/2>]
#=> ]>
#=> STEP 2 RESULT: #Stream<[
#=> enum: [1, 2, 3, 4, 5],
#=> funs: [#Function<48.51129937/1 in Stream.map/2>,
#=> #Function<48.51129937/1 in Stream.map/2>]
#=> ]>
#=> STEP 3 RESULT: #Stream<[
#=> enum: [1, 2, 3, 4, 5],
#=> funs: [#Function<48.51129937/1 in Stream.map/2>,
#=> #Function<48.51129937/1 in Stream.map/2>,
#=> #Function<48.51129937/1 in Stream.map/2>]
#=> ]>
#=> 11
#=> 22
#=> "22"
#=> 12
#=> 24
#=> "24"
#=> 13
#=> 26
#=> "26"
#=> 14
#=> 28
#=> "28"
#=> 15
#=> 30
#=> "30"
#=> ["22", "24", "26", "28", "30"]By adding a call to an Enum function, it forced our stream to evaluate. Notice that it performed all of the functions in the sequence to the first element in the list before moving to the second element in the list.
Here’s a different way to visualize what just happened.
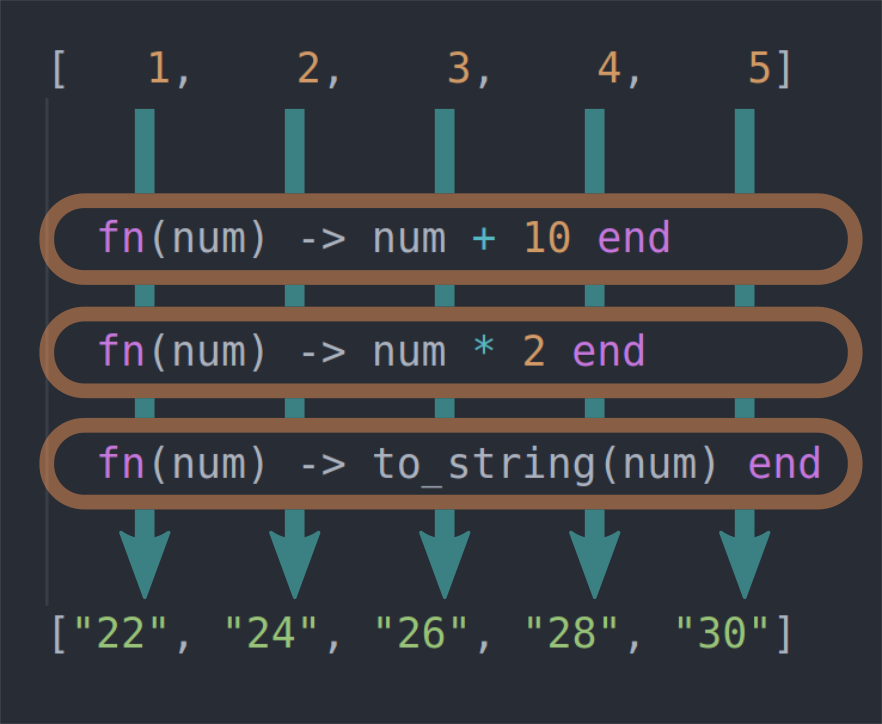
Each element in the list is piped through the sequence of functions we defined in our stream and the final value is used in the resulting list. Using this approach we never create the intermediate lists. Only 1 new list containing the final values is created.
When working with very large data sets, this can make a big difference to the memory consumption of your application!
When to use Enum vs Stream?
An obvious question to ask is “when do I choose one approach over the other?” Unfortunately, the answer isn’t always obvious. There are some clear occasions where Stream is the best option. Other times Enum performs better. There are plenty of scenarios where they are so similar that it doesn’t matter. There isn’t an absolute rule to follow here. As you play with it, you get a feel for it.
These next exercises aren’t problems to “solve”. They are opportunities to “play”. I setup some scenarios that give you a chance to play in IEx and develop your own feel for how these approaches compare. I’ll suggest some things to try and experiments to run. Feel free to tweak and run your own experiments as well!
Play time!
The playground equipment
First, let’s make sure you are comfortable with the playground equipment we will use here.
Location of the playground
Our playground is located in the lib/streams.ex file. Open it in your editor and look around.
Using IEx on the project
In a terminal window in the directory of the downloaded project file, enter the following:
iex -S mixThis starts an IEx session and loads the mix project into it so all the code is available to play with.
Executing a function and giving it some initial data looks like this:
CodeFlow.Streams.experiment_1_enum([1, 2, 3, 4, 5])
CodeFlow.Streams.experiment_1_enum(1..1_000)Tweaking the code
As you are playing and experimenting, you will likely have an “I wonder…” moment and want to tweak the code. Feel free! That’s what this is for!
Rather than killing and restarting the IEx session, you can trigger Elixir to pick up your code changes and recompile it while your IEx session is still running. Use the recompile function.
recompileTry it out. When you run recompile and no code changes were made, it returns a :noop. Meaning “no operation” was performed. If you made a code change, it returns :ok. Using recompile keeps you in the flow and experimenting.
Measuring the experiments
Let’s take a look at a simple experiment to see what it’s made up of.
def experiment_1_enum(data) do
simple_measurements(fn ->
data
|> Enum.map(&(&1 * 2))
|> Enum.map(&(&1 + 1))
|> Enum.map(&(&1 + 2))
|> Enum.map(&(&1 + 3))
|> Enum.map(&(&1 + 4))
|> Enum.map(&(&1 + 5))
|> Enum.map(&(&1 + 6))
|> Enum.map(&(&1 + 7))
|> Enum.map(&(&1 + 8))
|> Enum.map(&(&1 + 9))
|> Enum.map(&(&1 - 10))
|> Enum.to_list()
end)
endThis defines a series of Enum.map/2 functions. Why so many? Each call to Enum.map/2 creates an intermediate list with the results for that step. By having so many it helps exaggerate the differences. Tweaking that can be part of your experiments!
Note the experimental code is wrapped inside the simple_measurements function. An anonymous function passes in the experiment to run. The simple_measurements function does the following things for us:
- Forces a system-wide garbage collection to give us a standard baseline
- Prints out the amount of memory our process is consuming before running the experiment
- Tracks the time at start
- Runs the anonymous function that performs our experiment
- Tracks the time at stop
- Prints out the amount of memory our process is consuming after running the experiment
- Prints out the elapsed time in milliseconds
Here’s an example of the output.
CodeFlow.Streams.experiment_1_enum([1, 2, 3])
#=> 0.01 MB
#=> 0.01 MB
#=> 0 msec
#=> :okExecuting the function runs the experiment. I passed in a simple 3 element list of [1, 2, 3]. It printed out the starting RAM and ending RAM followed by the elapsed time. With such a small list, it doesn’t really even register. The experiments are designed to make it easy for you to play with different sizes of data and see the impact.
Also note that these are not proper scientific benchmarks. Run the same operation multiple times and you will see variations between the runs. The goal with this setup is to give you enough feedback from your experiments that you get a feel for how it behaves.
Now that you have been introduced to the playground, it’s time to try something!
Experiment #1
There are two functions for experiment #1. An Enum and a Stream version. Try running them both and compare.
CodeFlow.Streams.experiment_1_enum(1..1_000)
#=> 0.01 MB
#=> 0.14 MB
#=> 1 msec
#=> :ok
CodeFlow.Streams.experiment_1_stream(1..1_000)
#=> 0.01 MB
#=> 0.08 MB
#=> 1 msec
#=> :okWith a 1,000 item list, they both perform very quickly. The Enum version creates intermediate lists with all those steps. The RAM difference is noticeable but minor.
What do you think? Does it matter at this point which approach you’d choose?
Now try it with a much larger lists. Try these out:
1..1_000_0001..10_000_000
What differences did you observe? Notice that the elapsed time is about the same. What about the difference in RAM?
Experiment #2
In the previous experiment, our function returns a full list of however many items you said should be in the list. What if the work we do doesn’t return a list but a computed result? What does that do?
In experiment #2 we change the last line from Enum.to_list/1 to Enum.sum/1. Instead of returning the full list it sums all the numbers and returns the summed value.
Working with a list of 1,000 elements might look like this:
CodeFlow.Streams.experiment_2_enum(1..1_000)
#=> 0.01 MB
#=> 0.05 MB
#=> 1 msec
#=> :ok
CodeFlow.Streams.experiment_2_stream(1..1_000)
#=> 0.01 MB
#=> 0.04 MB
#=> 1 msec
#=> :okNow try it again with very large lists. Some suggested sizes again.
1..1_000_0001..10_000_000
How did returning a computed value differ from returning a list?
Try using a very small list [1, 2] and using IO.inspect/2 inside the Stream.map/2 calls to peer into what happens.
Reveal how to tweak the experiment if you’d like a shortcut.
You should see that the Stream version never builds a list of the values at all! That’s how the memory difference can be so large when working with large lists.
Experiment #3
Here’s another function to play with. Enum.take/2 takes a desired number of elements from an enumerable and returns them in a list.
What happens when I process a very large list but only want the first 5 elements in the result? That’s the idea we play with in this experiment.
Try it for yourself!
CodeFlow.Streams.experiment_3_enum(1..10_000_000)
CodeFlow.Streams.experiment_3_stream(1..10_000_000)Did you see a difference? Do you know why they behaved differently? Think about that for a minute before showing more explanation about it.
A Range is a stream too. It doesn’t expand to the full set of numbers when expressed like 1..100.
This also shows that a Stream can be stopped before visiting all the possible elements.
Experiment #4
The downloaded project includes a file in test/support/lorem.txt that contains 13MB of generated lorem-ipsum text.
The lorem.txt file gives us a chance to play with reading a large-ish file. Using the Enum approach, the entire file gets loaded into memory and operated on. Using the Stream approach we can read chunks of data or even just a line of text at a time.
This experiment takes each line of text and splits it into a list of words. It then gets a count of the number of words for each line. Finally, it sums the number of words on each line all together for a total number of words for the file.
Run both and see how they compare. Run it a few times until the times level out.
CodeFlow.Streams.experiment_4_enum()
CodeFlow.Streams.experiment_4_stream()What did you see happen? Why do you think it came out that way?
Built-in ways to start a stream
After playing with the experiments, hopefully you have a better sense of when to use Enum vs Stream. The next question you might ask is “What can be a stream”? Elixir’s standard library comes with some built-in functions for creating streams.
Here are few built-in ways to create a stream without using the Stream module.
File.stream!/3– Returns a stream for reading a file. Used in Experiment #4.IO.stream/2– Converts an IO device into a stream.Task.async_stream/5– Spawns a concurrent Task to process elements in the stream. Options let you tune how many concurrent tasks will run, etc. A good option when the task being performed is expensive and running in parallel makes sense.Ecto.Repo.stream/2– The Ecto database library can stream query results. Works well for processing potentially very large result sets.
Anything can be a stream
Using Stream.resource/3, potentially anything can become a stream. The resource/3 function takes in 3 functions to do the following:
- Setup the resource
- Get the next value from it
- Close or cleanup the resource
Examples of what you could use this to do:
- Fetch and process pages of JSON data from an external service. The “next” function can fetch the next page of data.
- Lazily parse a large CSV file – which is what the NimbleCSV library does.
- Stream and process very large files over the web – as this blog series demonstrates.
Recap
You took a different approach here. Instead of making failing tests pass, you spent time playing and experimenting with Enum and Stream to get a feel for how a Stream is different.
In many ways, a Stream acts like Enum. Both are enumerable, have functions for processing data, and more. However a Stream is different because it uses lazy evaluation.
You may not need to use a Stream often, but knowing what it is, how to use it, why it is different, and getting a feel for the kinds of problems it helps solve was our goal.
Consider using a Stream when you are working with data that would otherwise consume a lot of memory to process. Examples are:
- large lists
- large files
- large database result sets
- processing a potentially unbounded source
2 Comments
-
on April 26, 2021 at 10:13 pm
Very nice treatment of this complex topic.
-
on April 27, 2021 at 5:29 am
Thanks! I’m glad you enjoyed it! You don’t need streams very often, but when you do, it’s a huge benefit.
-
Comments are closed on this static version of the site.
Comments are closed
This is a static version of the site. Comments are not available.