Pipe Operator
Contents
"Hello" |> say()
The pipe operator is made up of these two characters: |>. There are two inputs to this operator. A left and a right side. The left side is an expression (or data) and the right side is a function that takes at least 1 argument.
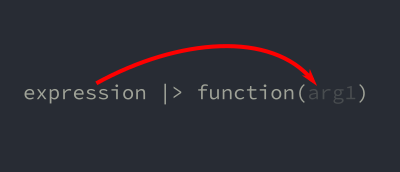
expression |> functionThe pipe operator performs a special job of putting the value of the expression on the left into the first argument of the function on the right.
This may not seem like much at first, but this is a very powerful and helpful feature. Let’s see it in action to start to understand what it does for us. The function String.upcase/1 takes a string and returns a new string with all the characters converted to upper case.
String.upcase("testing")
#=> "TESTING"This can be re-written using the pipe operator like so…
"testing" |> String.upcase()
#=> "TESTING"The pipe operator pushes the "testing" string in as the first argument to String.upcase/1.
Making a Pipeline
The real power with this operator is when we start chaining pipe operators together to create a “pipeline”. The result of one function can be piped into another function and then another.
Let’s look at a simple pipeline example:
" Isn't that cool? " |> String.trim() |> String.upcase()
#=> "ISN'T THAT COOL?"The real power with this operator is when we start chaining pipe operators together to create a “pipeline”.
If we re-write this without the pipe operator it looks like this:
String.upcase(String.trim("Isn't that cool?"))
#=> "ISN'T THAT COOL?"This is functionally equivalent. However, in order to read this code, we have to work from the inside out. Mentally parsing the function calls and the parenthesis to find the innermost argument and then start reading out from there. It’s more mental work. The pipe operator makes the process much more readable and intuitive!
The other way to re-write this is to use new variables at each step. It might look like this:
data = "Isn't that cool?"
trimmed = String.trim(data)
upcased = String.upcase(trimmed)
#=> "ISN'T THAT COOL?"This version reads easier because you still follow each step from the top going down instead of a sequence going from left to right. However, the pipe operator manages passing the return value from one step on to the next function for us, so we don’t need to keep binding it to a new variable.

The pipe operator is limited in IEx. Because IEx evaluates each line as it is entered, IEx can’t tell when a pipeline is finished or not. This means for simple code in IEx, we must write a pipeline with the pipe operator inline. If we define a module and a function then it will be evaluated all together and works as we’d expect.
Pipelines Flow from Top to Bottom
A pipeline is most readable when we write it vertically. We start with the data being passed in and build up our pipeline from there. For these to work in IEx, it must be declared in a module and a function. Open up your favorite text editor and write the code so you can paste into IEx. Here’s one you can copy to play with for a quick start.
defmodule PipePlay do
def test do
" Isn't that cool? "
|> String.trim()
|> String.upcase()
end
end
PipePlay.test()
#=> "ISN'T THAT COOL?"Do you see how it reads better? The pipeline can keep going by adding more steps.
IO.inspect/2
This is a good time to introduce a great debugging and insight tool. The IO module manages writing to standard out and standard error. We’ve already used IO.puts/2, this is where it is defined.
The function we want to look at now is IO.inspect/2. This does the following:
- Creates a string representation of whatever data structure we give it
- Writes it to
stdout(which prints it to the console) - Returns whatever value we passed in to it
These features make it a valuable function for peering into a pipeline and seeing the transformations being performed.
We’ll use a similar top-down pipeline that processes a string. Rather than only seeing the final result, we can sprinkle some IO.inspect calls directly into the pipeline. Since they pass on the data they were given, it is safe to insert almost anywhere. The side-effect that IO.inspect creates is to write the data to the console. This works really well for watching each step of the pipeline as it performs the transformations.
Try it out!
defmodule PipePlay do
def inspecting do
" PLEASE STOP YELLING! "
|> IO.inspect()
|> String.downcase()
|> IO.inspect()
|> String.trim()
|> IO.inspect()
|> String.capitalize()
end
end
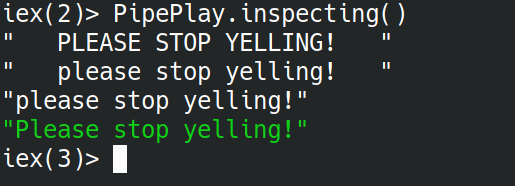
PipePlay.inspecting()
#=> " PLEASE STOP YELLING! "
#=> " please stop yelling! "
#=> "please stop yelling!"
#=> "Please stop yelling!"Running this in an IEx shell you might notice the difference in colors. The IO.inspect output is written to the terminal’s standard out. There is no text coloring added to this. The result of the function is recognized as a string and output with coloring. You might see something like this…
IO.inspect/2 works really well in a pipeline because it writes to stdout but returns the thing passed in. This can be used in many situations (not just pipelines) to get insight into what something is doing. Try it out and use it liberally!
The easiest way to sprinkle it around is to add the pipe and an IO.inspect call like |> IO.inspect() after something you want insight into. You don’t need to re-write code like IO.inspect(thing_to_peek_at), just use the pipe!
Example: thing_to_peek_at |> IO.inspect()
Understanding IO.inspect output
IO.inspect/2 doesn’t change the result of the function, it is a function who’s side-effect is to write data to the console.
IO.inspect/2 is best used during development and testing as a debugging and insight tool. You don’t want to leave this in production code. Assuming your application’s logs are captured and used, any calls to IO.inspect will create “console noise” that doesn’t conform to the logging pattern of your application. There are better ways to write data to your logs if that is your goal.
What about multiple arguments?
What about a function that doesn’t just take 1 argument? What if it takes 2 or more? The pipe operator handles putting the value into the first argument. Our call would be written as starting with the 2nd argument.
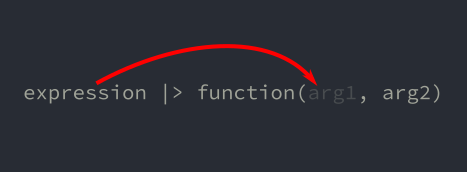
The function String.replace/3 takes 3 arguments. The first is the string to operate on. The 2nd is the pattern to match against (a string or regex) and the 3rd is the replacement string.
String.replace("I like Elixir!", "like", "love")
#=> "I love Elixir!"Written with the pipe operator, it looks like this:
"I like Elixir!" |> String.replace("like", "love")
#=> "I love Elixir!"We remove the first argument from the function on the right side of the pipe as it is put there for us. The first argument’s value is on the left of the pipe operator. We still include the 2nd, 3rd, and so on arguments if applicable.
Our current pipeline examples are operating on strings and String.replace/3 gives us a chance to include a function that takes more than 1 argument. Time for a practice exercise!
Practice Exercise
Write a module pipeline that starts with this initial string " InCREASEd ProdUCtivitY is HEar? " and performs the following operations on it.
- Trim off the spaces using
String.trim/1 - Give the string an initial capital letter using
String.capitalize/1. This also fixes the mixed case characters. - Replace the word
"hear"with"here"usingString.replace/3 - Replace the
"?"character with"!"usingString.replace/3 - Feel free to sprinkle in some
IO.inspectcalls to peek into the transformation pipeline
Custom pipelines
The Pipe Operator does a handy job of pushing the value on the left into the first argument of a function on the right. Pipe Operators can be chained together to create a “pipeline”. Pipelines become powerful when you define the functions used in the pipeline.
Pipelines with Local Functions
Up to this point, all the functions used in our pipelines are defined by the String module. We can further improve the readability of a pipeline when the functions are local to the module. Either they are imported to the module or declared there.
Let’s declare some simple add/2 and subtract/2 functions and use them in a pipeline.
defmodule PipePlay do
def perform do
1
|> add(3)
|> add(10)
|> subtract(5)
|> add(2)
end
def add(value1, value2) do
value1 + value2
end
def subtract(value1, value2) do
value1 - value2
end
end
PipePlay.perform()
#=> 11See how well that reads? The pipeline of transformations is clear and intuitive. Don’t disregard the point because our functions are simple in purpose. The same benefits exist when something more meaningful to your project is used.
Pseudo code example:
defmodule MyApp.Ordering do
# NOTE: pseudo-code only
def place_order(customer, item) do
customer
|> order(item)
|> allocate_inventory(item)
|> generate_invoice()
|> update_billing()
|> notify_customer()
end
endDon’t worry yet about how to implement something like the above example, we’ll get to that later.
Pipe-Friendly Functions
In order for a function to be pipe-friendly, it should return the first argument passed in. All the String functions we used take a string and return a string as the result. The Enum.map/2 functions take a list and return a list. Our add/2 and subtract/2 functions take a number in the first argument and return a number as the result.
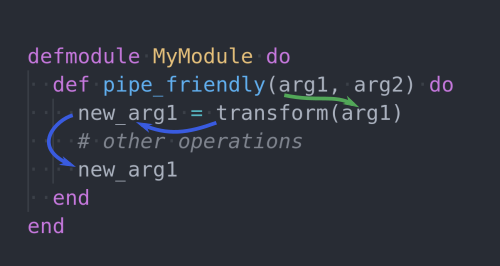
You will see this a lot in popular community libraries. When working with web requests in Phoenix or database queries using Ecto, to make something pipe-friendly, give some thought to the arguments passed in and the returned data from a function.
You will also notice functions like String.length/1 are most certainly not pipe-friendly. That’s okay, the function wouldn’t make sense to try and be pipe-friendly. The lesson here is to give a little extra thought when creating your functions and be deliberate about what is and is not designed to be pipe-friendly.
Recap
Let’s briefly review what we covered here:
- The Pipe Operator pushes the data on the left into the first argument of a function on the right.
- A series of pipes are combined to create a pipeline.
- Vertical pipelines are very readable.
- Local functions in pipelines are even more readable.
- Pipe-friendly functions return a transformed version of what they take in.
Creating custom functions that are pipe-friendly allow us to create custom pipelines that are tailored for our application and our problem.
We also covered how IO.inspect/2 can be a powerful pipe-friendly debugging and insight tool. Make both the Pipe Operator and IO.inspect/2 your new friends!
13 Comments
-
on April 8, 2021 at 8:00 am
I have been slowly learning to program and I have done more than a few Elixir lessons and tutorials on the pipe operator and nobody made the interesting point that maintaining the data type was preferable or pipe friendly. Excellent!
-
on April 8, 2021 at 8:30 am
Awesome! There are definitely examples where we won’t do that. Those are covered more explicitly in an upcoming lesson about the Railway Pattern. But it is super handy to make “pipe friendly” functions that keep the same first argument data type. Like a “Customer”, changeset, or other similar structures.
-
-
on January 22, 2022 at 6:22 am
Mark, I see that you have highlighting in iex (for example : ‘String’ is a yellow color, ‘uppercase’ is grey and “testing” is green). Do you use something special?! Like you know Ruby has irb, but also has pry… I use oh-my-zsh (everything is colorized) but when I enter in iex I have everything in green color only.
-
The code snippets here are colored using a fork of highlight.js. That makes it look nice but still be something you can copy-paste from when trying it out yourself. I don’t have any special coloring in my IEx as I type either. 🙂
-
on July 26, 2022 at 9:22 pm
For colour in IEX – create a
.iex.exsfile in your user folder (or your project folder if you don’t want it global) and paste the following code:timestamp = fn -> {_date, {hour, minute, _second}} = :calendar.local_time [hour, minute] |> Enum.map(&(String.pad_leading(Integer.to_string(&1), 2, "0"))) |> Enum.join(":") end IEx.configure( colors: [ syntax_colors: [ number: :light_yellow, atom: :light_cyan, string: :light_black, boolean: :red, nil: [:magenta, :bright], ], ls_directory: :cyan, ls_device: :yellow, doc_code: :green, doc_inline_code: :magenta, doc_headings: [:cyan, :underline], doc_title: [:cyan, :bright, :underline], ], default_prompt: "#{IO.ANSI.green}%prefix#{IO.ANSI.reset} " <> "[#{IO.ANSI.magenta}#{timestamp.()}#{IO.ANSI.reset} " <> ":: #{IO.ANSI.cyan}%counter#{IO.ANSI.reset}] >", alive_prompt: "#{IO.ANSI.green}%prefix#{IO.ANSI.reset} " <> "(#{IO.ANSI.yellow}%node#{IO.ANSI.reset}) " <> "[#{IO.ANSI.magenta}#{timestamp.()}#{IO.ANSI.reset} " <> ":: #{IO.ANSI.cyan}%counter#{IO.ANSI.reset}] >", history_size: 50, inspect: [ pretty: true, limit: :infinity, width: 80 ], width: 80 )-
Thanks Michael! That’s really helpful! I found what I believe is the original source of this config where it is explained in greater detail. https://samuelmullen.com/articles/customizing_elixirs_iex/
-
-
on February 19, 2025 at 10:10 am
Do you have a preferred font Mark? I accidentally found myself using Fira Code which has a very stylized pipe like a golf green flag
-
Hi Marcus! No, I use a pretty standard font. Enjoy!
-
-
-
-
on December 8, 2022 at 11:45 am
Hi, Mark!
I don’t get why String.length/1 is most certainly not pipe-friendly.
You mean that pipe-friendly functions don’t change the type of the argument, but String.length gets string and returns integer?-
Hi Sergey!
Really, it just depends on what you want from your pipeline. Here, I’m referring to passing in a string but returning an integer. You lose the ability to continue and operate on the string. So if the function being called keeps returning the primary type that was passing in (meaning the first argument), then it can continue to be piped in to a series of functions that all operate on that data structure, like with the customer example above.
-
on April 28, 2023 at 2:54 pm
Perhaps it would be a little less confusing to say that when the returned data type changes, you are mutating the pipe (from the original data type). Piping different values is pretty common when used in the right way, and pipelines certainly don’t need to maintain the same data type throughout. In this discussion, perhaps point out that it’s OK if you want to pipe the length of the string into the next function.
-
-
-
on March 31, 2025 at 1:04 pm
# Pipes and IEx
Not sure if this is some implementation on IEx after this course was created, but currently, you can simply pipe directly on a prompt and it will take the piped argument from the previous execution (line).
“`
iex(1)> ” Isn’t that cool? ”
” Isn’t that cool? ”
iex(2)> |> String.trim()
“Isn’t that cool?”
iex(3)> |> String.upcase()
“ISN’T THAT COOL?”
“`-
Hi Rodrigo! Yes, you are correct that IEX was later updated to allow piping on the next line like that.
-
Comments are closed on this static version of the site.
Comments are closed
This is a static version of the site. Comments are not available.