List
Contents
How it works
A List uses the [ and ] characters to contain the elements of the list separated by commas. It looks like this:
my_list = [1, 2, 3, 4, 5]This looks like an Array in other languages. However, a List doesn’t act like an Array.
A list in Elixir (and other functional programming languages) is actually a recursive data structure. Internally implemented as a linked list.
When you realize an Elixir list is an immutable linked list, it’s behavior makes sense and how you use it becomes clear.

my_list is “bound” to the list. The variable isn’t “assigned” the value of the list, it is said to be “bound”. Variables in Elixir are all “bound” to their values. You can think of “bound” as meaning “is pointing to”. So my_list is pointing to a specific element in a linked list. Each element points to the next element in the list and separately points to the value for the element.
When you realize an Elixir list is an immutable linked list, it’s behavior makes sense and how you use it becomes clear.
In many languages, it is common to add more items to the end of an Array as it is built up. With an immutable List, we can’t add items to the end as that would be affecting other variables that are bound to some element earlier in the list.

If I really do want to add to the end of the list, I can, but a whole new list is created with that value at the end. When a list is very large, this becomes an expensive operation. Two lists can be concatenated together using the ++ operator.

my_list ++ [6]
#=> [1, 2, 3, 4, 5, 6]Adding to the front of the List, or the “head” is very cheap. It doesn’t alter other variables that are already bound to some element in the List.

This makes it very efficient both in speed and memory consumption. To efficiently add to the front of a list, you use the | pipe character to join the new element and the existing list together.
[0 | my_list]
#=> [0, 1, 2, 3, 4, 5]It can be cheaper and faster to build up a large list in reverse, adding to the “head” rather than re-building the whole list with each new addition. Then, once built, perform a single “reverse” of the whole list using Enum.reverse/1.

Enum.reverse([6, 5, 4, 3, 2, 1])
#=> [1, 2, 3, 4, 5, 6]
Thinking about a list as a “linked list” data structure where it’s made up of pointers to the actual data helps to understand how immutable data can work and be so memory efficient. The same kind of thing is happening with the other data structures, but I think it’s easiest to start imagining it with a list.
Working with immutable data may be a different experience for you. It probably feels uncomfortable. However, it is what enables concurrency and immutable data removes a whole category of state related bugs. If it is uncomfortable now, just know that understanding and embracing it will help make you a better programmer. And you’ll end up loving it!
See for yourself!
I described how adding to the front of a list is faster than adding to the end. The best way to really “get” this is to see and feel it for yourself.
Below I have 2 one-liner functions that exaggerate the differences so you can really feel it. Don’t worry about understanding the details of the code. Conceptually they both build a list of 100,000 items. They both add one number at a time to the list starting with the number 1 and going up to 100,000.
The difference is one function adds the item to the end of the list using list concatenation. That’s the code that says acc + [n]. It means list_so_far ++ [next_number].
Run this line in IEx and expect it to take some time.
Enum.reduce(1..100_000, [], fn(n, acc) -> acc ++ [n] end)Did you see how long that took?
Running Observer (it’s like an activity monitor built in to the BEAM), you can see the load it put on the machine.
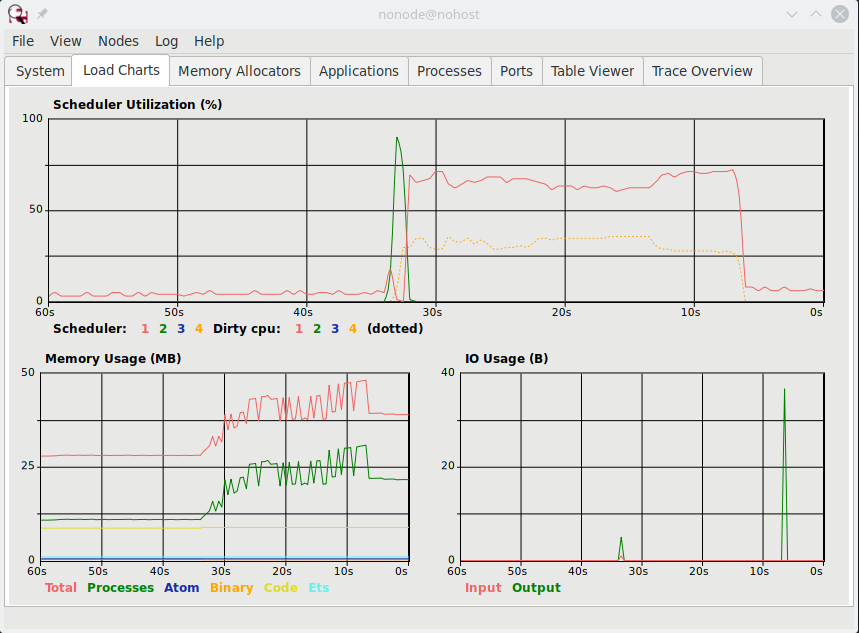
The top chart shows the CPU impact and how much time it took. The bottom left chart shows the RAM impact. The saw-tooth line is from garbage collection being done.
Why is it so inefficient? With every item added, it re-creates the entire list so no other references to the list are affected.
Let’s try it again with code adds items to the front of the list. The important part of the code is the [n | acc] which means [next_number | list_so_far]. It adds the single item to the front of the list.
Run this line in IEx and see how long it takes to return.
Enum.reduce(1..100_000, [], fn(n, acc) -> [n | acc] end)Did that feel different? Let’s see the system impact of the code.
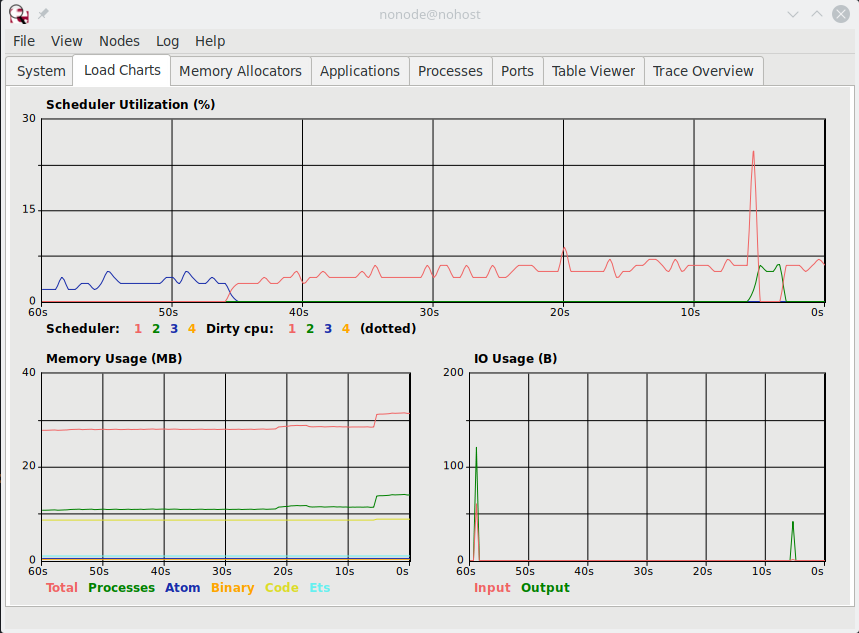
Notice the chart scale is reduced and that the CPU has one spike that stayed below 30%. The RAM also only slightly bumped.
Why is it so much more efficient? As the list is being built, it never gets re-created. Any other variable references to the list made during this operation won’t be affected by adding more items to the front. So it can just keep adding items to the front efficiently.
Should I only ever add to the front?
You might see this and ask, “should I only ever add items to the front of a list?” The answer is “no”. This example is specially designed to exaggerate the behavior. When building a list of 10, 100, or even 1,000 items, adding to the end of the list probably won’t even be noticed. However, it is important when working with much larger lists.
The point here is to understand how lists work in Elixir so you have the right mental model. Lists are internally implemented as linked list, not an array. You can’t treat them like an array.
List Contents
Lists don’t just contain integers. Lists can contain any data type and can contain different types from one element to the next.
A list’s contents are ordered. They remain in the order they are declared.
[1, "Hello", 42.0, true, nil]Experiment with Lists
Take some time to experiment with lists in IEx. Try concatenating lists together with ++, you can also remove elements from a list using --. Try adding to the front of a list using the | pipe separator. Try tweaking the list function examples to use different numbers. Experimentation is playing! Have fun playing!
7 Comments
Leave a Comment
You must be logged in to post a comment.
Could you please explain why it is too complex operation appending at the end of the list taking an example here.
I have been reading many times people saying it is not recommended to append, but no reason and examples why it is so.
The recommendation of not adding to the end of a list is particularly a factor on larger lists. The entire list structure must be re-created to ensure immutability. Re-creating a small list is cheap, so while it still may be less effective on a short list, it would never be noticed and is not a problem.
I didn’t include this kind of code in the lesson because the code used in the example hasn’t been covered or explained yet. However, if you’d like to play with this yourself here are two 1-liners that demonstrate it.
list = Enum.reduce(1..100_000, [], fn(n, acc) -> [n | acc] end)This code builds up a list 1 item at a time up to 100,000 items. At each step, the item is added to the front of the list.
This next line of code builds up the list by adding to the end. This causes the list to be re-created 100,000 times. As the list grows, it becomes a more expensive operation.
list = Enum.reduce(1..100_000, [], fn(n, acc) -> acc ++ [n] end)Feel free to run both in IEx. Even without benchmark times you will see and feel the difference.
You will notice in the IEx output that the version adding to the front has the list in reverse order. Perhaps you want the list to be
[1, 2, 3, 4, ...]. This next line is an adaptation of the first, more efficient one. It efficiently builds up a large list, then re-creates the list 1 time and reverses the order.list = Enum.reduce(1..100_000, [], fn(n, acc) -> [n | acc] end) |> Enum.reverse()You end up with a much faster operation overall and the items are in the desired order. It’s a good question. I hope that answers it for you.
That sounds great!
By the way Good example. It is a practical proof.
What I understood after reading your reply is…
[n | [1,2,3,4]]like herenis pointing to the first element of the list asListin elixir is a `linked_list`. So, we no need to duplicate the the array[1,2,3,4]as we can directly point to the first element in the list. At this point we are having only extran->[1,2,3,4]in memory.In the case of
[1,2,3,4] ++ [n]we are having[1,2,3,4]and[1,2,3,4,n]in the memory .Correct me If I am wrong.
Best regards!
That’s correct. It duplicates the data to ensure other references aren’t affected. Adding to front still allows other references to be unchanged and doesn’t duplicate the list. If you open up your system’s Activity Monitor, you can watch the “beam” process while it churns on the slow example. The CPU is hit hard but the RAM climbs and drops and climbs again. Garbage collection is cleaning up the memory that isn’t being referenced.
Conclusion: when working with large lists of data, a basic understanding of how Lists work underneath makes for a better experience.
In my opinion, Elixir will always create a new list no matter you add elements to the front or at the end. This is because list is an immutable data structure in Elixir. The reason why adding an element at the end is taking more time and CPU cycles is because Elixir has to traverse the entire list to add the element. The head of the list only knows about the next element. It does not know location of the last element. So for example in the list [a,b,c,d,e] element a only knows how to locate 2 and element 2 only have location of element 3..
In first scenario, the list addition operation can be seen as:
[] => [a] => [a,b] => [a,b,c] => [a,b,c,d]
So for first addition Elixir is not traversing any element, for second addition its traversing 1 elements (only a) and so on. The traversal length is increasing with every iteration.
However in second scenario Elixir is not traversing the list at all as we are adding elements to the head (first position) every time.
When a list (or other complex data structure) is modified within a single process in Elixir, it doesn’t usually create a new copy. When data is sent between processes, it does create a copy. Let’s prove that it doesn’t create a copy.
Let’s create a really large list so it exaggerates the time to create and work with the list.
This creates a list with 100,000,000 elements. Notice how long it takes to create the list once. It isn’t an immediate operate. You can watch it take a long time.
list_1 = Enum.to_list(1..100_000_000)Now let’s add a single item to the head. How much time does it take?
list_2 = [0 | list_1]It takes no time! I doesn’t make a copy! “Immutable” doesn’t mean everything is copied. It means that once a data structure is created, it isn’t allowed to change that instance of the data structure.
Let’s add one to the end.
list_3 = list_1 ++ [0]This takes a long time because it has to create a whole new copy of the list. Yes, it has to iterate over the elements of the list, but why wouldn’t it take time to add it to the front if it still had to make a copy?
You can see that each list still has the unmodified set of items. list_1 and list_2 have different elements. If we actually looked at the amount of RAM used by the process, we would also see that list_1 made it grow but list_2 doesn’t. I cover things like that in more detail in Code Flow.
Here’s the point. Because the data is immutable (not allowed to change), there are optimizations that can be made to actually re-use the previous data structure. Because it can be counted on to NOT CHANGE. This is both faster (CPU) and smaller (RAM).
Hope that helps!
Correct me if I’m wrong: The idea of immutability is like the idea of sound in the question “If a tree falls in a forest, and there’s no one around to hear it, does it make a sound?”, if we assume the answer is ‘no’. ‘Making a sound’ means doing something that people hear (or at least can hear). If a list changes and there is nothing pointing to it, it is as if it never changed. If you put an item at the beginning of a list, nothing from the past is pointing at that item. However, if you put the item at the end of a list, items on the list, plus any items pointing to the beginning of the list, will be indirectly pointing at that item, unlike before the item was appended. That sort of situation is what needs to be avoided in order to maintain immutability and that is why a new copy has to be created.